Can you build tables in Apache Spark with the same ease and familiarity as you would using standard SQL? The answer is a resounding yes, and understanding how to leverage this capability is fundamental to efficient data manipulation and analysis within the Spark ecosystem.
The CREATE TABLE statement, a cornerstone of SQL, finds its equivalent within the Spark SQL environment, allowing you to define tables within an existing database. This opens up a world of possibilities, enabling developers to seamlessly integrate SQL queries with Spark programs. This integration facilitates easier work with structured data through a language already familiar to many: SQL. Whether you're using Hive formats, working with internal, external, or Delta tables, or leveraging the power of dataframes, Spark offers a versatile approach to table creation and management.
To begin working with Spark SQL effectively, the initial steps revolve around creating a database and then a table. Once these foundational elements are in place, the subsequent phase involves loading and querying the data that populates the newly created table. The process encompasses a range of methods and options, designed to cater to diverse needs and scenarios within the Spark framework. This article provides a comprehensive guide to navigating these aspects.
Let us explore how to create tables in Spark, including examples of internal, external, and Delta tables, and how to utilize both SQL and DataFrame commands effectively. We will also investigate the nuances of creating tables using various file formats, such as Parquet, and the impact of compression algorithms like Snappy.
| Category | Details |
|---|---|
| Table Creation Methods |
|
| Table Types |
|
| Syntax and Commands |
|
| Data Sources |
|
| Storage Formats & Options |
|
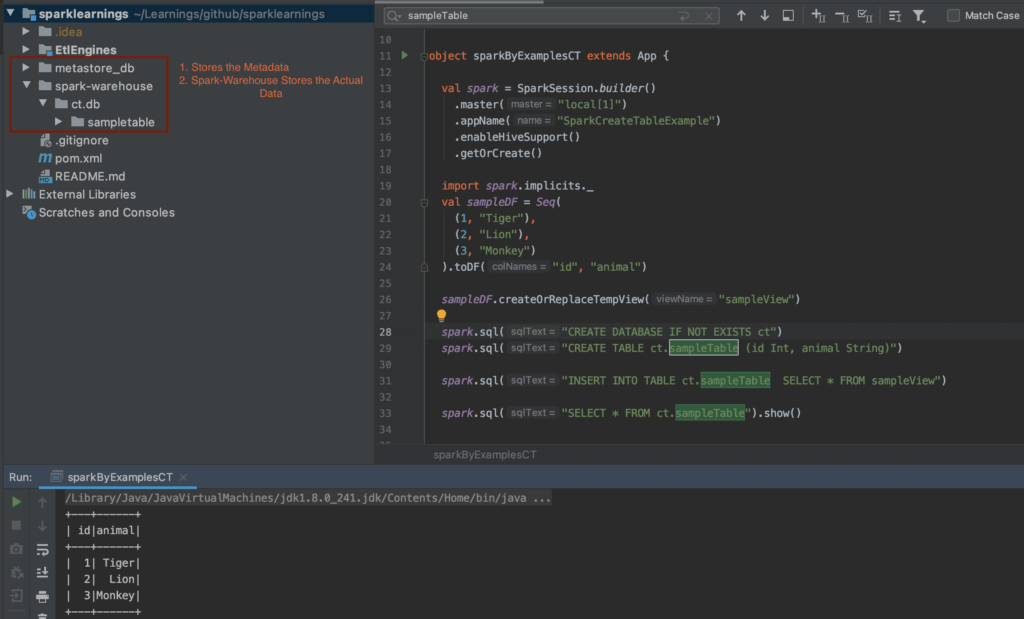
The CREATE TABLE statement in Spark SQL mirrors its standard SQL counterpart, yet it harnesses Spark's unique features and syntax capabilities. This means you can create tables using familiar SQL commands while benefiting from Spark's distributed processing power. Consider this example, it would create a table in a sales schema called customer: CREATE TABLE sales.customer USING delta AS (SELECT 'john' AS fn, 'smith' AS sn, 55 AS age). If a schema isn't specified, the table defaults to the standard Spark location. Furthermore, using Delta Lake offers the advantages of ACID transactions, which ensure data consistency and reliability, which is crucial in environments that require robust data management.
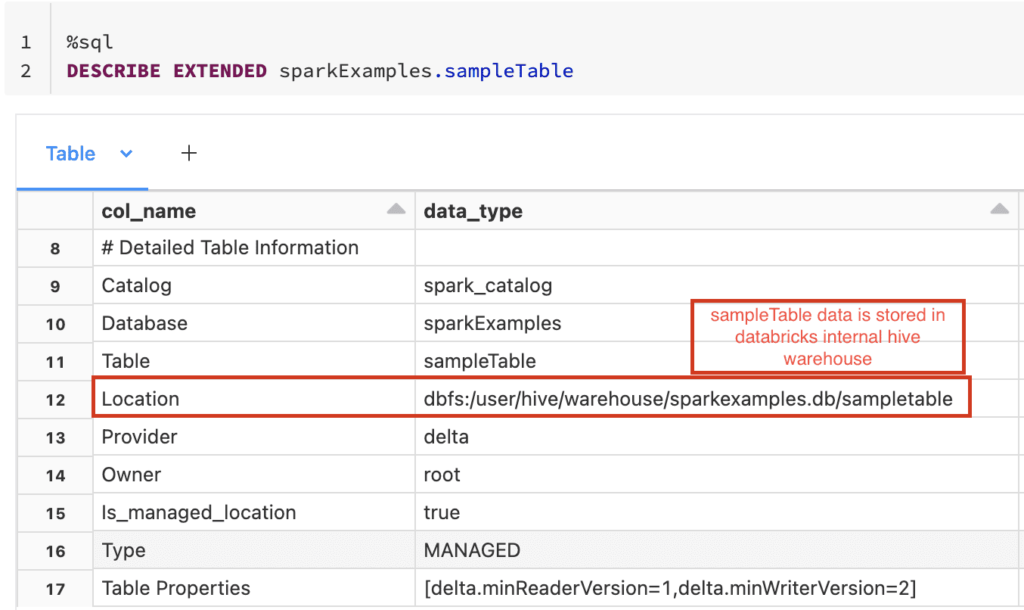
The core of table creation often involves the CREATE TABLE AS SELECT (CTAS) command, which generates a new table and populates it with the output from a SELECT query. This streamlines the process of transforming and loading data into a new table. Another approach is to define the table's schema and then load data into it using a separate operation. Both internal and external tables are supported, offering flexibility in managing data. Internal tables store both the data and metadata within Spark's management, while external tables allow you to define a table that points to data stored externally.
When specifying the location for an external table, you must provide the path to the data. This approach is beneficial when you want to work with data already stored in a specific location without Spark managing the data files. With managed tables, Spark is responsible for the data files location and management.
Data sources are specified by the 'source' and a set of options. If the source is not specified, the default data source, configured by spark.sql.sources.default, will be utilized.
When working with Iceberg tables, the primary interface for interaction is SQL. The primary interface for interacting with Iceberg tables is SQL, therefore, most examples will combine Spark SQL with the DataFrames API. The same is true when writing Iceberg tables, Spark SQL and DataFrames can be used to create and add data. For example, you can create a table "foo" in Spark which points to a table "bar" in MySQL using a JDBC data source. When you read/write table "foo", you actually read/write table "bar". In general, CREATE TABLE is creating a "pointer", and you need to make sure it points to something existing.
Spark SQL facilitates the creation and management of temporary views. The CREATE OR REPLACE TEMP VIEW command creates tables within the global_temp database. To efficiently manage these, remember to modify queries to point to the global_temp database if necessary, for example, "CREATE TABLE mytable AS SELECT FROM global_temp.my_temp_table". This is important when working with temporary tables that need to be accessed across multiple Spark sessions.
The examples provided cover how to use the Apache Spark spark.sql() function to execute arbitrary SQL queries. These queries can range from basic SELECT statements to more complex operations, such as creating and manipulating tables. The spark.sql() function is essential for integrating SQL syntax within Spark programs, enabling you to query SQL tables directly within the code. It's a versatile tool for performing various data operations within Spark.
Working with Delta Lake tables requires some specific considerations, and the table configuration is derived from the location if data is present. In essence, when defining Delta Lake tables, any TBLPROPERTIES, table_specification, or PARTITIONED BY clauses must perfectly align with the Delta Lake structure and configurations. If you're looking to alter the table structure, particularly involving ACID-compliant formats, consider creating a new table with specific properties, copying the data from the original, deleting the old table, and then renaming the new table to match the original's name. This approach ensures that the table is created within the correct format.
The usage of the spark.sql() function extends to dropping tables as well. Using Spark.sql(DROP TABLE IF EXISTS + my_temp_table) ensures that a table is removed if it exists before recreating it or performing other operations. This is useful in cleaning up temporary tables or making sure an older version isnt interfering with a new process.
For Hive tables, the storage format is crucial as it governs how data is read from and written to the file system. You need to define the input and output formats, impacting performance. The CREATE TABLE AS SELECT (CTAS) functionality can create tables and populate them with the results of a query, offering a streamlined way to ingest data. When defining tables using CTAS and setting a location, and if the given location is non-empty, Spark will throw an analysis exception. However, setting spark.sql.legacy.allowNonEmptyLocationInCTAS to 'true' will allow Spark to overwrite the existing data at the location with the results of your query, ensuring that the created table contains the same data as the input query.
Furthermore, you can work with different file formats such as Parquet, to create tables for specific purposes. For example, when creating a table using the Parquet file format, by default, the files are compressed using the Snappy algorithm, which balances compression efficiency and performance. You can use the appropriate file format for the task at hand, ensuring both efficiency and data integrity.
Additionally, you can create tables using a select statement. Here's an example of how you might accomplish this within a PySpark environment. You'll start by importing the necessary modules and initializing a SparkSession object:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
After creating the SparkSession, you can use the spark.sql() function to run SQL queries. These can include:
- Selecting all columns and rows:
result = spark.sql("SELECTFROM people")result.show() - Selecting specific columns and all rows:
result = spark.sql("SELECT name, age FROM people")result.show()
In addition to the basic setup, you can employ various techniques to join multiple tables using DataFrames, generate aggregations with a GROUP BY clause, and rename columns. This is commonly done to merge and condense different datasets.
In cases where you are working with existing lakehouse tables, you can create new views to simplify data access. For instance, to create a new workspace with your warehouse and lakehouse data, you would first create a table, load the data, and then establish views for easier query access.
The source of a table can be configured by specifying the 'source' and associated options. If no source is specified, Spark defaults to the configuration set by spark.sql.sources.default. External tables are created when a path is specified, using the data already present at the given path. Managed tables are created when the path is not specified. When a table is created, ensure that it points to something that already exists. For example, if you are trying to read from table "foo", you may be pointing to table "bar" if using JDBC, hence in general the CREATE TABLE command creates a "pointer" to ensure it is pointing to something existing.
In conclusion, creating and managing tables in Apache Spark is a powerful capability that brings SQLs familiarity and Sparks performance together. The ability to define the table structure, choose appropriate data sources and formats, and leverage the spark.sql() function ensures effective data manipulation and analysis, making it easier to work with large datasets and complex queries. Whether you are starting a new project or working on existing data, Spark SQL offers a rich set of tools for creating and managing tables.